
This experiment takes advantage of the repulsive nature of diamagnetic materials, specifically those of pyrolytic graphite. We will levitate a piece of pyrolytic graphite on a diamagnetic sled to create a model of a sled-based launcher that uses electromagnetism to launch paper airplanes. We will build the actual launcher using the same design as our model, but replacing the permanent magnets in our diamagnetic checkerboard sled with electromagnets, and levitating an aluminum plate instead of a piece of pyrolytic graphite.
Why the checkerboard design?
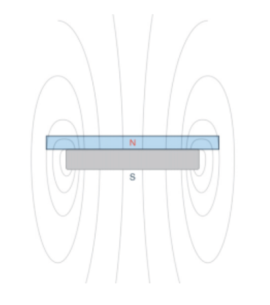
Now that we understand why certain materials have certain magnetic properties, we can analyze the magnetic field itself. In a permanent magnet, the magnetic field travels from the south pole to the north pole. The orientation of the magnetic field in a magnet affects its efficiency. For example, much of the energy in a conventional magnet is wasted in product design, as illustrated in the figure below.
However, if we arrange the magnets in a checkerboard pattern we can make our own version of a polymagnet, which is a programmable magnet in which magnetic structures that incorporate correlated patterns of magnets with alternating polarity are designed to achieve a desired behavior. In doing so, the magnetic field is more contained, and all parts of it are used along the length of the magnet checkerboard. This will be the fundamental concept behind our diamagnetic sled.
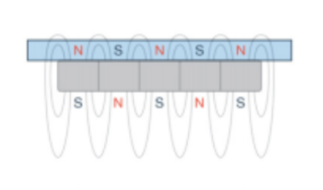
The diamagnetic sled consists of 32 permanent magnets that are ¾ long x ¾ wide x 3/8 inches thick. These magnets are lined along a thin piece of steel to keep them from flipping over on each other. They are oriented in the previously mentioned checkerboard pattern. We will levitate a piece of pyrolytic graphite because pyrolytic graphite is the strongest diamagnetic material with regard to induced field strength since it has the largest diamagnetic constant.
Stability of Diamagnetic Checkerboard
Model Design
Materials: (still need to add measurements, pictures, demo videos)
- Steel plate
- 32 permanent magnets
Pyrolytic graphite
Works Cited
“Diamagnetism and Paramagnetism.” Boundless. N.p., n.d. Web. 12 May 2016.
K&J Magnetics
“What Is a Polymagnet?” Polymagnet Correlated Mag