When it comes to user profiles—ad preferences, interests, taste profiles—the relevant data are usually available in their relatively “raw” state. This could be individual, atomic google searches, youtube videos watched, songs played, locations visited.
What’s usually not directly available:
- Mid-level representations: histograms, frequencies, time-series plots
- Exceptions:
- Facebook allowed me to see my “interests,” the content tags that determine my news feed. These are probably a slight aggregation of “raw” clicks and interactions. (matching them to predetermined tags) (see Facebook screenshot)
- Spotify generates mid-level personalized content, such as the “On Repeat” playlist, which lists your 30 most played songs from the last 30 days. This is likely just a very small portion of all the mid-level representational information computed by Spotify. (see Spotify screenshot)
- Usage statistics (phone, browser, etc.) are usually directly available in histogram form.
- Generating mid-level representations from available “raw” data would take some work; in most cases it would be possible, but also infeasible for most.
- Sometimes, 3rd-party applications exist to do this for some type of data: for example, I used a chrome extension to produce a representation of my browsing history. (see browsing history screenshot)
- Without 3rd-party assistance, generating mid-level representations (or even downloading the data in a form that allows manipulation) is likely unreasonable for most users who may be interested in them.
- Exceptions:
- High-level, abstract, latent representations: membership in the groups by which advertisers and other data-buyers understand us. These are only available to an entity (like a social media company) with access to many user profiles, which can be jointly analyzed for latent variation.
- Obtaining this information may be within the realm of theoretical possibility for a very motivated individual using a site such as Twitter with large amounts of public, scrapeable data, but decidedly outside of the realm of possibility for the vast majority.
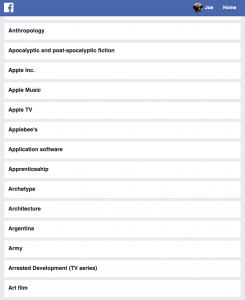
Some of my interests, (likely) based on Facebook interactions, used for ad targeting
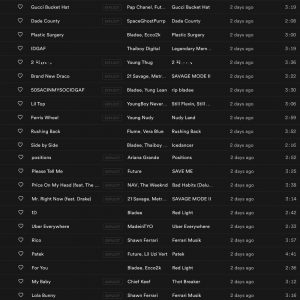
Most of my “On Repeat” playlist based on the last 30 days of Spotify use, part of the listening data used to recommend new music
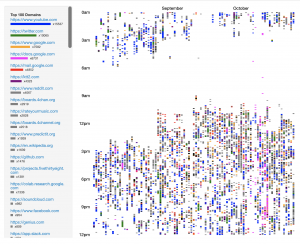
My last 3 months of browsing history, visualized by day and by time of day; also frequency tallied by website on the left. Unclear exactly what it is used for
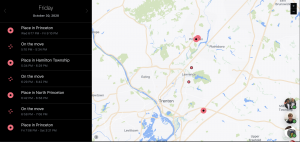
My location on Friday, as tracked by Facebook, who purportedly uses this data as part of its ad targeting
Opacity of data usage
- Most opaque: location tracking—performed by Facebook and Google (by default), both of which do not exhaustively announce the uses of that data
- Least opaque: probably taste profiles like those constructed by YouTube and Spotify, both of which openly use algorithms to recommend new content to users.
Feedback
- Most obvious data collection featuring feedback is in Facebook, Spotify, and YouTube, where the generation of preferences and the consumption based on those preferences occur in a very tight feedback loop—on the scale of the consumption of individual units of content.
- The feedback loop involving browsing history is much less clear, and likely occurs on a much larger scale, both in terms of time and in terms of user base. The output of Google’s webpage-ranking algorithm, for example, evolves based on links between webpages and trends in searching across its billions of users.