For my data journal, I was presented with the daunting task of distilling my digital footprint into a few screenshots and a single, cohesive post. From clickstream data to financial transactions, there were innumerable data sets to choose from, each one representing a different aspect of my behavior and personality. As such, for the purpose of this post, I decided to restrict my analysis to the three most invasive forms of data mining monitoring my daily life. Thus, I will be examining the data “exhaust trails” collected by my Health app, intelligent alarm clock, and Alexa in order to examine the implications of Greenfield (2016)’s “pixelated person”.
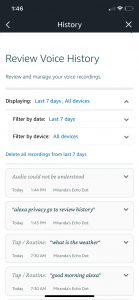
To start, I first inspected the Alexa located in my dining room to try to determine the degree of surveillance I am subjected to. Over the past 7 days, my Alexa reportedly made 36 different recordings of my family’s conversations, averaging out to around 5 recordings a day. I was actually not aware that they are legally allowed to record me and considering the limited amount of time my family spends in that room each day, this statistic is truly deeply concerning. In fact, the phrase “alexa privacy go to review history” from the screenshot’s second data entry is literally a direct quote from when I was instructing my sister on how to obtain this data. Although most of the recordings provided in the Alexa app were of mundane and admittedly insignificant interactions, it begs the question: if Alexa has publicly demonstrated a capacity for this sort of panoptical surveillance, what are they recording and listening to without disclosing to the consumer? This challenges the validity of the consumer’s consent by interrogating the informed status of relationship and agreement.
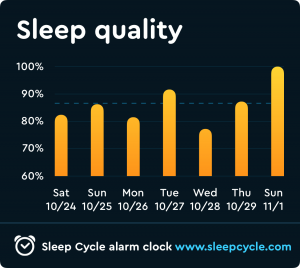
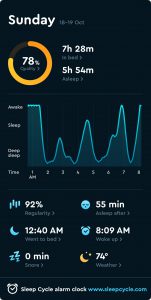
To further illustrate the invasiveness of my digital surveillance, I similarly chose to examine an app called “Sleep Cycle” that monitors my REM cycle and sleeping patterns in order to assess the quality of my rest and identify the least abrasive time to administer my alarm. In this case, I was complicit in my surveillance, as I willingly forfeited my privacy in order to enjoy the practical advantages associated with my sleep’s datafication. As such, I find Sleep Cycle’s corporate surveillance to be less disconcerting despite the intimate nature of the information, which speaks to the incentives facilitating this collective encroachment of our rights. In many ways, Sleep Cycle gathers more personal information than Alexa, as it does everything from tracking what time I went to bed to recording my snoring whenever I have a stuffy nose. As exhibited by the provided screenshots, the app monitors the ambient temperature of my room, my body’s response to auditory stimulus, and the “regularity” of my sleep at any given point in my REM cycle. However, personally, this is still not nearly as alarming as Alexa’s omnipresent, panoptical surveillance, at least not at first glance. This once again underscores the importance of informed participation and supports the argument against the increasing prevalence of what I refer to as “one click consent”.
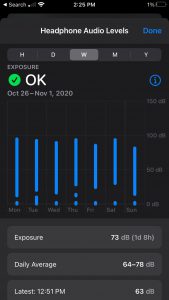
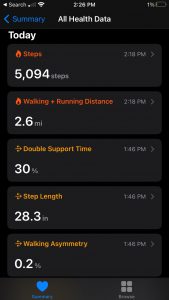
Lastly, for this post, I decided to provide some of the health data collected by Apple’s fully integrated “Health” app. Data from this app will likely be extensively discussed in other posts given its importance in the iOS ecosystem, so I will only briefly touch on the information and insight it provided. That said, I thought it provided a valuable encapsulation of the inverse correlation between technologization and privacy. Of course, the app recorded my daily number of steps and the distance I travel on a daily basis. However, beyond that, the app also calculated my estimated step length, my walking speed, the asymmetry of my gait, and my average headphone level. Although conceptually I was aware that my activity, from the location of my cursor to the time it takes me to swipe through a series of Snapchat stories, is all tracked by someone, to see my unconscious behavior unknowingly quantified and displayed was jarring, regardless of its possible benefits. Even though I was cognizant of their sophistication when I upgraded to AirPods from simple headphones, I never considered that it would retain information of our interactions. As more “smart” devices become integrated into the technological landscape, this will undoubtedly occur with increasing regularity, emphasizing the necessity for a more thorough consideration of their potential consequences.
In conclusion, my data journal supports the conception of the “pixelated person” by demonstrating how intense data mining can delimit a well-rounded, incredibly detailed depiction of an individual. Furthermore, it is important to keep in mind that we are only interpreting data these companies have willingly disclosed, which suggests that these representations are probably even more complex and nuanced in reality. Given the astonishing granularity of the collected data, at a certain point, it becomes almost impossible to separate the person from their representation. After all, how am I different from my heartbeat? Through this exercise, I was not only reminded of the unrelenting, unblinking gaze of digital surveillance, but also alerted to the centrality of consent which it comes to defining the relationship between technology and the individual. If consent is coerced, irrevocable, and uninformed, then it was never truly given. Thus, future policy solutions should aim to target this erosion by implementing stringent transparency requirements. That said, there are still some lingering points of uncertainty. Would a consumer or industry-oriented solution be more effective? Is it even possible to mitigate digital surveillance at this point? How are we supposed to hold corporations accountable for their surveillance when we can’t even do so for our own government? I’m looking forward to hearing all of your insights tomorrow!
“Alexa” Data:
“Sleep Cycle” Data:
“Health” Data:
Hi Zack! I very much enjoyed reading your post. One of your comments that really intrigued me is when you stated, “there were innumerable data sets to choose from, each one representing a different aspect of my behavior and personality.” I really identify with this statement, because during the exercise I was realizing that the pixilated me was not what I view as “myself;” while the exercise showed me data that I didn’t know about myself, I didn’t feel as though I “identified” by my data.
Your statement made me question, if someone put all the data pixilations of myself together, and an individual analyzed or made visualizations of them, would they know “me?” I think this question ties back into our discussion yesterday when (I think it was Cynthia, sorry if I got it wrong!) brought up the distinctions between data and narrative in terms of correlation and causality. I’m wondering, in an “ideal world,” if there was a way to data-fy all aspects of a person, and include a temporal aspect in terms of what behaviors and personalities arose, if it would just end up constituting what we view as narrative.
Thank you so much for your post, Zack, because I am now thinking a lot about what the difference is between an individual and their identity; what are your thoughts? Is the alexa surveillance data something you consider as “yours” but not a part of your “identity”?